Week 1
Building a human detection exercise
Before trying out anything more demanding, it was essential to start off with building a basic inference prototype for the human detection exercise. This incudes everything from choosing the correct model architecture, preprocessing the inputs and planning out the required output specifications for postprocessing. Since the work of the core application would be to infer on the uploaded model, it becomes important to agree upon a common input/output specification. I looked around for some common input/output specifications used by some of the well known object detection models and here’s what I found:
- Tiny YOLOv2 - This model is a real-time neural network for object detection that detects 20 different classes. It is made up of 9 convolutional layers and 6 max-pooling layers.
- Input shape - (1x3x416x416)
- Output Shape - (1x125x13x13)
- Postprocessing of output tensor - As mentioned above, the output is a (125x13x13) tensor where 13x13 is the number of grid cells that the image gets divided into. Each grid cell corresponds to 125 channels, made up of the 5 bounding boxes predicted by the grid cell and the 25 data elements that describe each bounding box (5x25=125).
- Single Stage Detector - This model is a real-time neural network for object detection that detects 80 different classes.
- Input shape - (1x3x1200x1200)
- Output shape - boxes: (1x’nbox’x4), labels: (1x’nbox’), scores: (1x’nbox’)
- SSD-MobilenetV1 - SSD-MobilenetV1 is an object detection model that uses a Single Shot MultiBox Detector (SSD) approach to predict object classes for boundary boxes.
- Input shape - This model does not require fixed image dimensions. Input batch size is 1, with 3 color channels. Image has these variables: (batch_size, height, width, channels).
- Output shape - Given each batch of images, the model returns 4 tensor arrays:
- num_detections
- detection_boxes
- detection_scores
- detection_classes
- RetinaNet - RetinaNet is a single-stage object detection model.
- Input shape - The model expects mini-batches of 3-channel input images of shape (N x 3 x H x W), where N is batch size.
- Output shape - Model has 2 outputs:
- Classification heads: 5 tensors of rank 4, each tensor corresponding to the classifying anchor box heads of one feature level in the feature pyramid network.
- Bounding box regression heads: 5 tensors of rank 4, each tensor corresponding to the regressions (from anchor boxes to object boxes) of one feature level in the feature pyramid network.
- YOLOv2-COCO - This model aims to detect objects in real time. It detects 80 different classes from the COCO Datasets.
- Input shape - (1x3x416x416)
- Output shape - (1x425x13x13)
- Postprocessing of output tensor - The output is a (1x425x13x13) tensor where 13x13 is the number of grid cells that the image gets divided into. Each grid cell corresponds to 5 anchors, made up of the 5 bounding boxes predicted by the grid cell and the 80 classes that describe each bounding box (5 x (80 classes + 5) = 425).
Out of all these, the specifications of SSD-MobilenetV1 seemed to me to be the most appropriate for the exercise as they are well formatted and broken into parts, which makes them relatively easy to specify and post process on. Also, a lot of users would only want to fine tune on a pre existing model architecture according to their liking rather than building one from scratch. This makes the input/output specifications of SSD-MobilenetV1 appropriate as it is pretty famous with relatively more resources available on the internet regarding it’s fine tuning. I will cover more on how to fine tune a model later in some other post.
Coding the core application
Coding the core application code for performing inference required the following steps:
- Exporting the SSD-MobilenetV1 model to ONNX format
- Preprocessing the input
- Running inference
- Postprocessing the outputs
Exporting the SSD-MobilenetV1 model to ONNX format
You can download the pre trained SSD-MobilenetV1 model from tensor flow detection model zoo here.
# python script
import os
import sys
ROOT = os.getcwd()
WORK = os.path.join(ROOT, "work")
MODEL = "ssd_mobilenet_v1_coco_2018_01_28"
os.makedirs(WORK, exist_ok=True)
# shell script
pip install --user -U tf2onnx
# Download the pre trained model. Skip this part if you've already downloaded it manually as stated above
cd WORK; wget -q http://download.tensorflow.org/models/object_detection/MODEL.tar.gz
cd WORK; tar zxvf MODEL.tar.gz
# Converting the model to ONNX
python -m tf2onnx.convert --opset 10 --fold_const --saved-model WORK/MODEL/saved_model --output WORK/MODEL.onnx
Preprocessing the input
The following code shows how preprocessing was done.
# Getting the image input from hal.py
img = self.hal.getImage()
# Scaling down the image to reduce processing overhead
img_resized = cv2.resize(img, (300,300))
# reshaping the image to add a batch size of 1
img_data = np.reshape(img_resized, (1, img_resized.shape[0], img_resized.shape[1], img_resized.shape[2]))
Running Inference
import onnxruntime as rt
sess = rt.InferenceSession(self.aux_model_fname)
# input layer name in the model
input_layer_name = sess.get_inputs()[0].name
# list for storing names of output layers of the model
output_layers_names = []
for i in range( len(sess.get_outputs()) ):
output_layers_names.append(sess.get_outputs()[i].name)
# Inference
# We will get output in the order of output_layers_names
result = sess.run(output_layers_names, {input_layer_name: img_data})
detection_boxes, detection_classes, detection_scores, num_detections = result
Postprocessing the outputs
Given each batch of images, the model returns 4 tensor arrays as output:
num_detections : the number of detections.
detection_boxes : a list of bounding boxes. Each list item describes a box with top, left, bottom, right relative to the image size.
detection_scores : the score for each detection with values between 0 and 1 representing probability that a class was detected.
detection_classes : indicating the index of a class label.
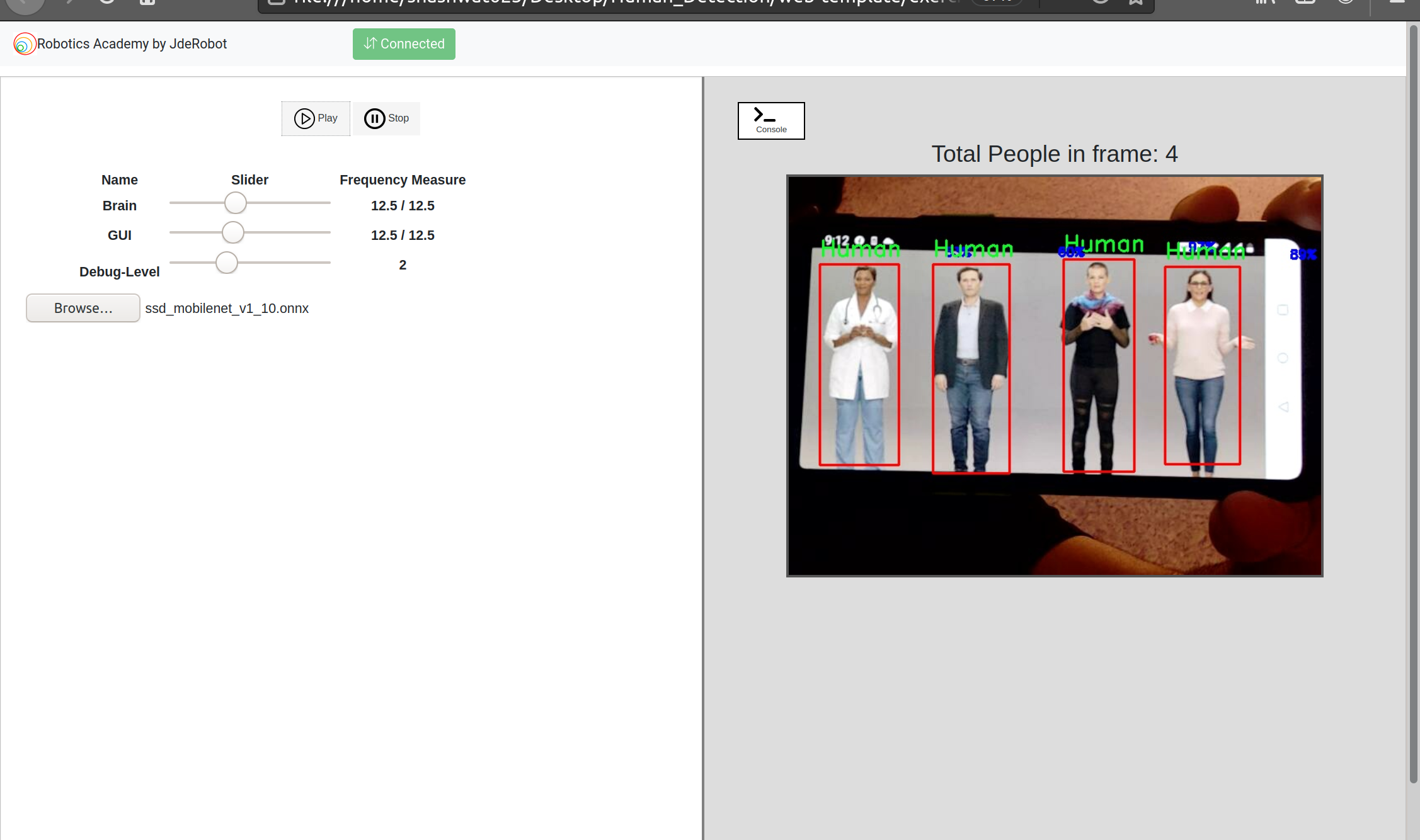
def display_output_detection(self, img, detections, scores):
"""Draw box and label for 1 detection."""
# The output detections received from the model are in form [ymin, xmin, ymax, xmax]
height, width = img.shape[0], img.shape[1]
for i,detection in enumerate(detections):
# the box is relative to the image size so we multiply with height and width to get pixels.
top = detection[0] * height
left = detection[1] * width
bottom = detection[2] * height
right = detection[3] * width
top = max(0, np.floor(top + 0.5).astype('int32'))
left = max(0, np.floor(left + 0.5).astype('int32'))
bottom = min(height, np.floor(bottom + 0.5).astype('int32'))
right = min(width, np.floor(right + 0.5).astype('int32'))
cv2.rectangle(img, (left, top), (right, bottom), (0,0,255), 2)
cv2.putText(img, 'Human', (left, top-10), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0,0,255), 1)
cv2.putText(img, str(scores[i])+"%", (left+150, top-10), cv2.FONT_HERSHEY_DUPLEX, 0.4, (255,0,0), 1)
self.gui.showResult(img, str(""))
batch_size = num_detections.shape[0]
for batch in range(0, batch_size):
for detection in range(0, int(num_detections[batch])):
c = detection_classes[batch][detection]
# Skip if not human class
if c != 1:
self.gui.showResult(img, str(count))
continue
count = count + 1
detections.append(detection_boxes[batch][detection])
scores.append(detection_scores[batch][detection])
self.display_output_detection(img, detections, scores)
Working Demo